
하네스 엔지니어링은 점점 똑똑해지는 LLM과, 막상 써보면 답답한 현실 사이의 간극을 메우는 가장 중요한 기술이다. 모델 교체만으로는 절대 해결되지 않는 영역이다.
GPT-5, Claude Opus 4.6, Gemini 3까지 매달 벤치마크 기록이 갱신된다. 그런데 정작 내 프로젝트에 붙여 쓰면 엉뚱한 함수를 호출하고, 규칙을 잊어버리고, 같은 실수를 반복한다. 왜 이런 괴리가 생기는지 그 원리와 해법을 5가지 관점에서 정리한다.
모델은 똑똑한데 왜 내 AI는 멍청한가

벤치마크 점수와 실제 체감 성능은 전혀 다른 차원의 이야기다. MMLU나 SWE-Bench 점수가 오르는 속도와, “내 프로젝트에서 AI가 유능하게 느껴지는 속도”는 거의 무관하다고 해도 과언이 아니다.
모델의 지능이 10 오르는 동안, 내가 모델에게 건네는 맥락의 질은 그대로인 경우가 대부분이기 때문이다. 엔진만 페라리로 바꾸고 바퀴는 손수레 바퀴를 그대로 쓰는 셈이다.
근본 원인: LLM은 입력 토큰만 본다
LLM은 그 순간 주어진 입력 토큰 외에는 아무것도 모른다. 내 머릿속에 있는 프로젝트 구조, 코딩 컨벤션, 어제 내린 의사결정, 이 고객사의 특수한 제약은 토큰으로 들어가지 않으면 존재하지 않는 것과 같다.
인간 개발자라면 “아, 우리 프로젝트는 원래 이렇게 하잖아요”라고 암묵적으로 합의되는 것들이, LLM에게는 매번 처음 듣는 얘기다. 멍청해 보이는 것이 아니라, 맥락이 없는 것이다.
착각의 함정
“모델이 똑똑해졌으니까 대충 말해도 알아듣겠지”라는 기대가 모든 실망의 출발점이다. 오히려 모델이 똑똑해질수록, 불충분한 맥락에서 “그럴듯하게 지어내는” 능력까지 같이 올라가기 때문에 환각은 더 정교해진다.
트랜스포머: 다음 토큰 확률 기계
하네스 엔지니어링을 이해하려면 먼저 트랜스포머의 본질을 직시해야 한다. 2017년 구글의 “Attention is All You Need” 논문 이후 모든 주요 LLM의 뼈대가 된 이 구조는, 놀랍도록 단순한 목표를 가지고 있다. 지금까지의 토큰을 보고 다음 토큰의 확률 분포를 계산하는 것. 그게 전부다.
관련 논문 링크
https://arxiv.org/abs/1706.03762
Self-Attention의 작동 원리
트랜스포머의 핵심은 Self-Attention이다. 입력된 각 토큰은 다른 모든 토큰과의 관련도를 계산한다. 이때 Query, Key, Value 세 개의 벡터가 만들어지고, Query와 Key의 내적으로 “이 토큰이 저 토큰을 얼마나 중요하게 봐야 하는가”라는 가중치가 결정된다.
그 가중치에 Value를 곱해 합치면 “문맥이 반영된 새로운 표현”이 나온다. 이 과정이 수십 층에 걸쳐 반복되면 우리가 “문맥 이해”라고 부르는 현상이 만들어진다. 하지만 그 본질은 여전히 확률적 패턴 매칭이지, 이해가 아니다.

벡터 기반 추론의 본질
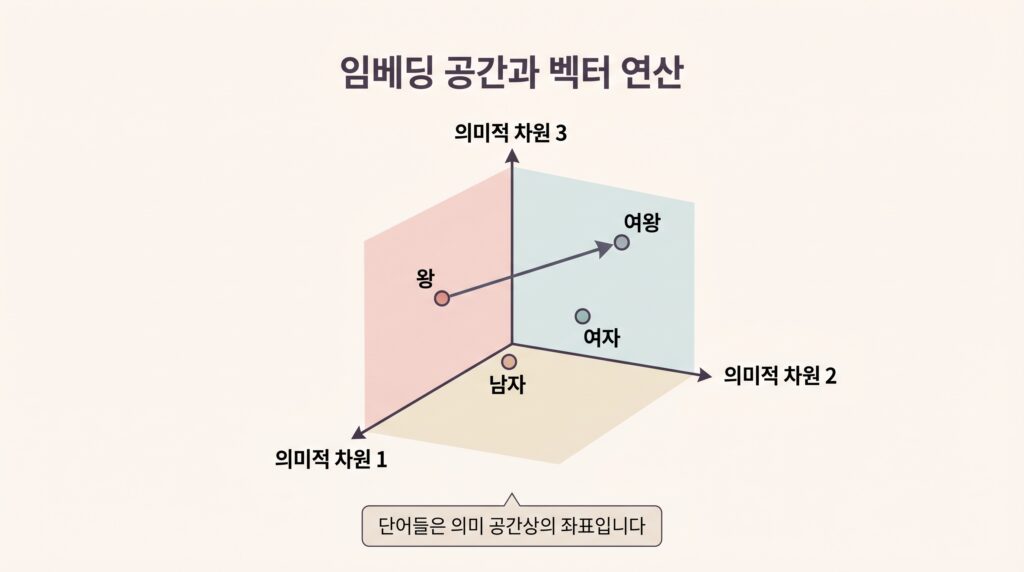
트랜스포머가 다루는 모든 단어, 문장, 코드 조각은 고차원 벡터로 임베딩된다. Claude나 GPT 같은 모델은 보통 수천 차원의 공간에서 의미를 표현한다. 유명한 예시인 “왕 – 남자 + 여자 = 여왕”이 성립하는 이유는, 단어들이 의미 공간 위의 좌표로 변환되어 산술 연산이 가능해졌기 때문이다.
추론이 아니라 기하학
- 모든 토큰은 의미 공간의 한 점으로 매핑된다
- “비슷한 의미”는 “공간에서 가까운 거리”로 표현된다
- 모델은 이 공간에서 가장 그럴듯한 다음 점을 예측한다
- 따라서 입력 벡터의 질이 출력 벡터의 질을 곧바로 결정한다
여기서 결정적인 통찰이 나온다. 모델 자체의 지능을 끌어올리는 것보다, “어떤 벡터를 입력으로 넣느냐”를 설계하는 것이 체감 성능을 훨씬 더 크게 움직인다는 사실이다. 같은 모델이라도 입력 맥락이 정제되어 있으면 놀라울 만큼 유능해지고, 그렇지 않으면 멍청해진다.
하네스 엔지니어링이 필요한 이유
여기서 하네스 엔지니어링이 등장한다. Harness는 원래 말을 제어하는 “마구”를 뜻한다. AI 맥락에서는 LLM을 감싸, 실제로 일을 할 수 있게 만들어주는 시스템 전체를 의미한다. 모델은 토큰 예측만 할 뿐, 스스로 파일을 열거나 명령을 실행하거나 상태를 기억하지 못한다. 그 모든 것을 대신해 주는 껍데기가 하네스다.
하네스가 감싸는 것들
하네스의 영역은 생각보다 넓다. 도구 호출(Tool Use), 권한 관리, 세션과 Context 유지, Memory(CLAUDE.md 같은 영속 지침), 파일·명령 실행 인터페이스, 샌드박스, 에러 피드백 루프가 모두 여기에 포함된다. 이 중 어느 하나라도 부실하면 모델이 아무리 똑똑해도 체감 성능은 추락한다.
Claude Code라는 대표 사례
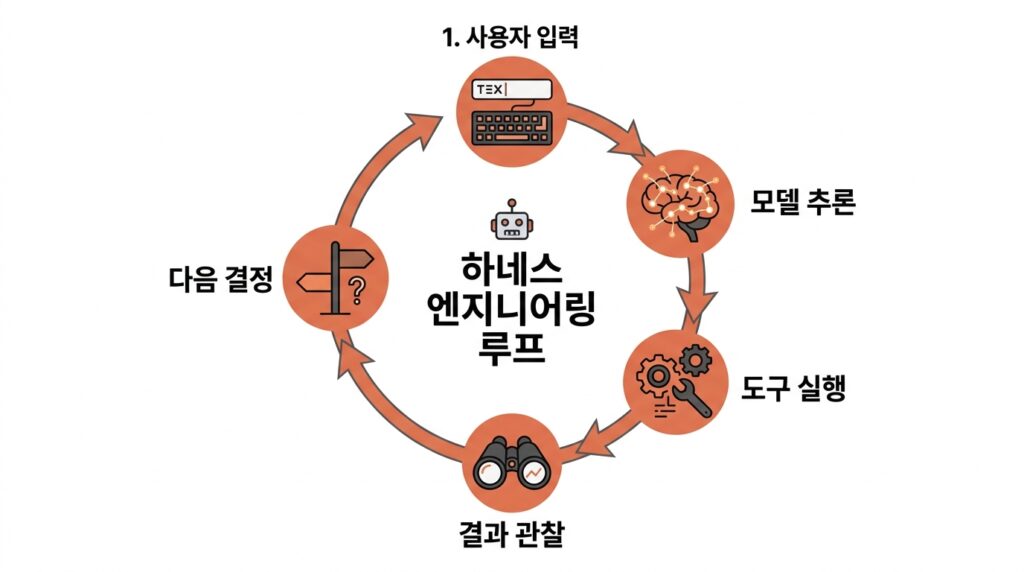
Anthropic의 Claude Code는 대표적인 Agentic Harness다. 사용자 입력을 받으면 모델이 추론하고, 필요한 도구를 호출하고, 결과를 관찰한 뒤 다음 판단으로 이어지는 Agentic Loop를 반복한다. 이 루프의 설계 품질, 즉 하네스의 품질이 곧 “Claude Code가 얼마나 유능해 보이는가”를 결정한다. 똑같은 Claude 모델을 API로 직접 호출할 때와 Claude Code로 쓸 때 체감이 전혀 다른 이유가 바로 이것이다.
“`html
API 직접 호출 vs Claude Code: Harness Engineering 관점
같은 claude-opus 모델이라도 “모델을 어떻게 감싸서 쓰느냐(harness)”에 따라 결과물의 질과 행동이 크게 달라진다. Harness란 모델 위에 얹히는 시스템 프롬프트, 도구, 컨텍스트 관리, 루프 제어 같은 비-모델 레이어 전체를 말한다.
시스템 프롬프트 (가장 큰 차이)
Raw API 호출: 개발자가 넣은 system 메시지가 전부다. 비워두면 모델은 “범용 어시스턴트” 모드로 동작한다.
Claude Code: 수천 토큰 규모의 정교한 코딩 전용 시스템 프롬프트가 주입된다. “파일을 수정하기 전에 먼저 읽어라”, “사용자 코드 스타일을 따라라”, “추측하지 말고 확인하라”, “불필요한 주석을 달지 마라”, “테스트를 돌려서 검증하라” 같은 행동 규약이 박혀 있다. 이게 같은 모델을 “코딩 에이전트”로 변신시키는 핵심이다.
도구 세트 (Tool Surface)
API: 도구는 개발자가 직접 정의해야 한다. function calling 스펙을 짜고, 실행 루프도 직접 구현한다.
Claude Code: Read, Edit, Write, Bash, Glob, Grep, WebFetch, Task(서브에이전트) 등이 이미 큐레이션되어 있다. 각 도구의 description이 모델에게 “언제 무엇을 써야 하는지”를 학습시키는 역할을 한다. 특히 Edit은 단순 문자열 치환이 아니라 정확한 매칭/유니크성 검증 로직이 붙어 있어서 모델의 환각을 강제로 잡아낸다.
Agentic Loop 제어
API: 한 번 호출하면 한 번 응답한다. 멀티턴 도구 사용을 하려면 개발자가 while loop, tool_result 주입, 종료 조건 판단을 직접 짠다.
Claude Code: 자체 agent loop가 돌아간다. 도구 호출 → 결과 관찰 → 다음 행동 결정을 모델이 자율적으로 반복한다. 컴팩션(context 압축), 토큰 예산 관리, 인터럽트 처리, 권한 승인(--dangerously-skip-permissions 같은) 게이트가 다 harness 레벨에 있다.
컨텍스트 주입
API: 컨텍스트는 messages 배열에 들어간 것만이 전부.
Claude Code: 작업 디렉토리, git 상태, CLAUDE.md(프로젝트 규약 파일), 최근 수정 파일, 환경 정보가 자동으로 컨텍스트에 합류한다. CLAUDE.md는 사실상 “프로젝트별 시스템 프롬프트 확장”으로 작동한다. 프로젝트 루트에 CLAUDE.md를 잘 써두면 매번 같은 지시를 반복할 필요가 없어지는 이유가 이거다.
출력 형식 강제
API: 모델은 마크다운, 코드블록, 산문 등 자유롭게 답한다.
Claude Code: CLI 환경에 최적화돼 있어서 답변이 짧고, 불필요한 preamble(“좋은 질문입니다…”)이 제거되며, 코드 변경은 도구로 처리하고 채팅에는 요약만 남기도록 강하게 튜닝돼 있다.
정리
같은 모델이지만 Claude Code는 시스템 프롬프트 + 도구 + 루프 + 컨텍스트 자동 주입 + 출력 규율이 통합된 “코딩 특화 harness”다. API 직접 호출은 “맨몸의 모델”이고, 같은 수준의 코딩 에이전트를 만들고 싶다면 이 5개 레이어를 직접 재현해야 한다. 그래서 Cursor, Cline, oh-my-claudecode 같은 도구들이 각자 다른 harness 철학으로 같은 모델을 다르게 부려먹는 거다.
실전 하네스 엔지니어링 설계 원칙
내 AI를 덜 멍청하게 만들고 싶다면, 모델 교체가 아니라 내가 쓰는 하네스를 다듬어야 한다. 실전에서 통하는 다섯 가지 원칙을 제시한다.
다섯 가지 원칙
- Context를 명시하라. 프로젝트 규칙, 코딩 컨벤션, 도메인 용어, 금지 사항을 CLAUDE.md나 시스템 프롬프트에 못 박는다. 암묵지를 문서화하는 만큼 AI가 똑똑해진다.
- Memory를 분리하라. 세션마다 휘발되어야 할 정보와 영속되어야 할 정보를 명확히 구분한다. 모든 것을 장기 기억에 쌓으면 Context Window가 쓰레기통이 된다.
- 도구를 제한하라. 필요한 도구만 노출해 판단 공간을 좁혀라. 100개의 MCP 툴을 붙이는 것보다 5개의 정제된 툴이 훨씬 낫다.
- 루프를 짧게 유지하라. 한 번에 하나의 목표만 맡기고, 거대한 태스크는 작은 단위로 쪼개라. Context가 길어질수록 모델은 산만해진다.
- 관찰을 자동화하라. 실패 로그, 테스트 결과, 린터 출력을 다음 Context에 자동으로 되먹여라. 하네스는 결국 피드백 루프의 품질 싸움이다.
이 다섯 가지만 제대로 지켜도, 같은 모델이 갑자기 두세 배 똑똑해진 것처럼 느껴진다. 체감 지능은 모델이 아니라 하네스가 만든다.
함께 보면 좋은 의사 운영 사이트
교육, 개원 준비, 홈페이지 제작, 의사 커뮤니티까지 운영에 도움이 되는 사이트를 모았습니다.
-
의사를 위한 통증교육
doctormodu.com → -
의사를 위한 모든 교육
academy.doctormodu.com → -
개원 전 필수패키지
감잡, 통증, 피부, IVNT 모든 족보모음
doctornote.kr → -
의사를 위한 홈페이지 제작
doctorbrand.kr → -
의사들을 위한 소통공간
doctorlounge.kr →