멀티에이전트 구현하기 7단계 실전 가이드
멀티에이전트 구현하기는 하나의 거대한 AI에게 모든 일을 몰아주는 방식보다 훨씬 유연한 시스템을 만들 수 있다는 점에서 주목받고 있다. 특히 복잡한 업무 자동화, 문서 분석, 고객 응대, 콘텐츠 생산 같은 분야에서는 문제를 잘게 나누고 각 역할에 맞는 에이전트를 배치하는 방식이 성능과 유지보수 측면에서 유리하다.
단순히 에이전트 수를 늘린다고 좋은 결과가 나오지는 않는다. 실제로는 역할 정의, 메시지 전달 방식, 결과 검증, 실패 처리, 비용 통제까지 함께 설계해야 한다. 이 글에서는 멀티에이전트 시스템을 처음 설계하려는 개발자와 실무자를 위해 구조, 구현 방식, 운영 팁까지 한 번에 정리한다.
멀티에이전트 구현하기가 중요한 이유
단일 에이전트는 초기 구현이 쉽지만, 업무가 복잡해질수록 프롬프트가 비대해지고 책임 범위가 모호해진다. 반면 멀티에이전트 시스템은 각 에이전트가 명확한 임무를 맡기 때문에 추론 품질과 재사용성이 올라간다. 예를 들어 조사 담당, 초안 작성 담당, 검토 담당, 게시 담당을 분리하면 각 단계의 오류를 더 쉽게 찾아낼 수 있다.
복잡한 워크플로를 병렬화할 수 있다
멀티에이전트 구현하기의 가장 큰 장점 중 하나는 병렬 처리다. 하나의 요청을 여러 하위 작업으로 분해하고 동시에 처리하면 응답 시간을 줄일 수 있다. 예를 들어 상품 설명 생성 작업에서 시장 조사, 경쟁사 분석, 카피 초안 작성, 법률 검토를 따로 돌리면 전체 파이프라인 효율이 높아진다.
책임 분리가 품질 개선으로 이어진다
책임이 분리되면 평가 기준도 분명해진다. 리서치 에이전트는 정확성, 작성 에이전트는 가독성, 검수 에이전트는 정책 준수 여부에 집중할 수 있다. 이 방식은 프롬프트 엔지니어링보다 시스템 설계가 중요해지는 시점에서 특히 강력하다.
멀티에이전트는 “AI를 여러 개 붙이는 기술”이 아니라 “역할과 흐름을 설계하는 기술”에 가깝다.
멀티에이전트 구조를 먼저 설계하는 법
멀티에이전트 구현하기를 시작할 때 가장 먼저 해야 할 일은 코드 작성이 아니라 구조 정의다. 어떤 입력이 들어오고, 누가 판단하며, 누가 실행하고, 누가 검증하는지를 순서도로 그려야 한다. 이 단계가 없으면 나중에 에이전트끼리 책임이 겹치거나, 같은 정보를 여러 번 요청하는 비효율이 생긴다.
기본 아키텍처는 허브 앤 스포크가 무난하다
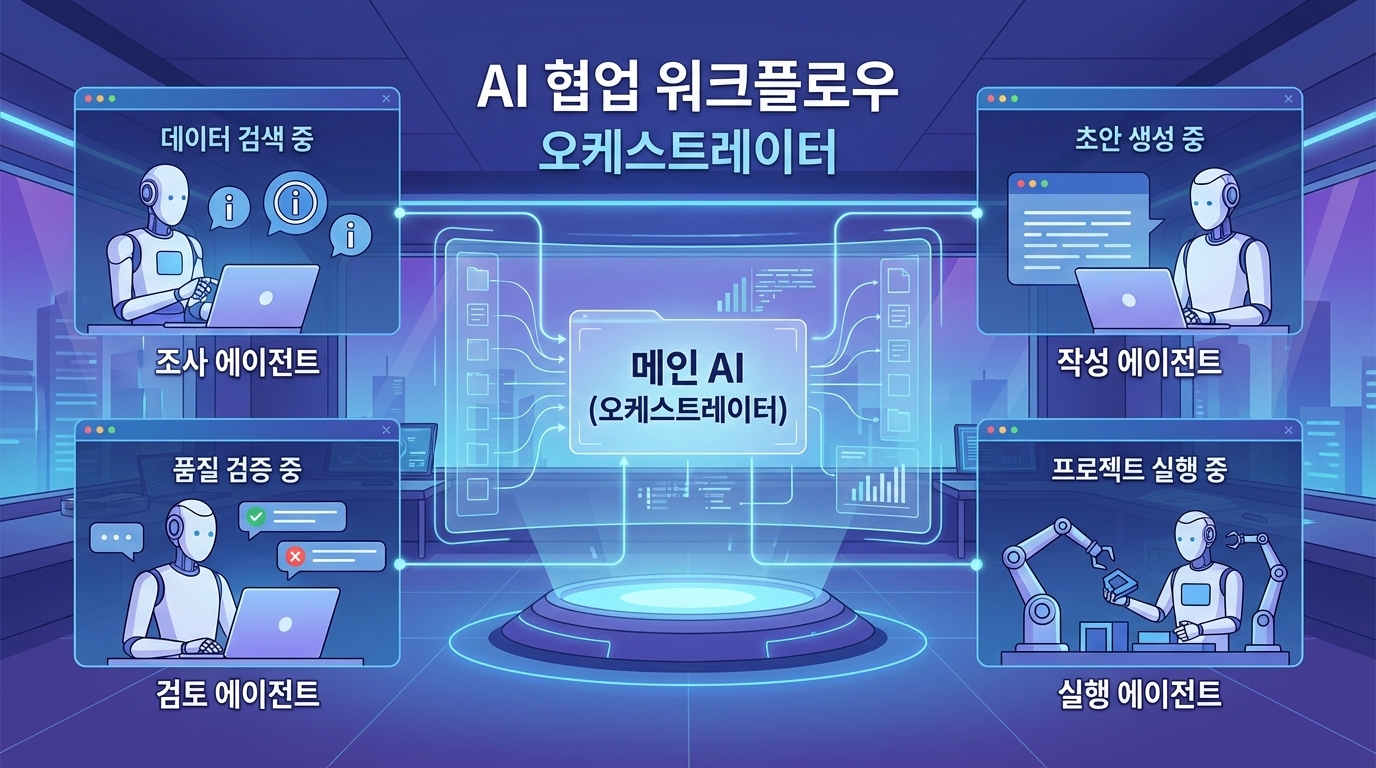
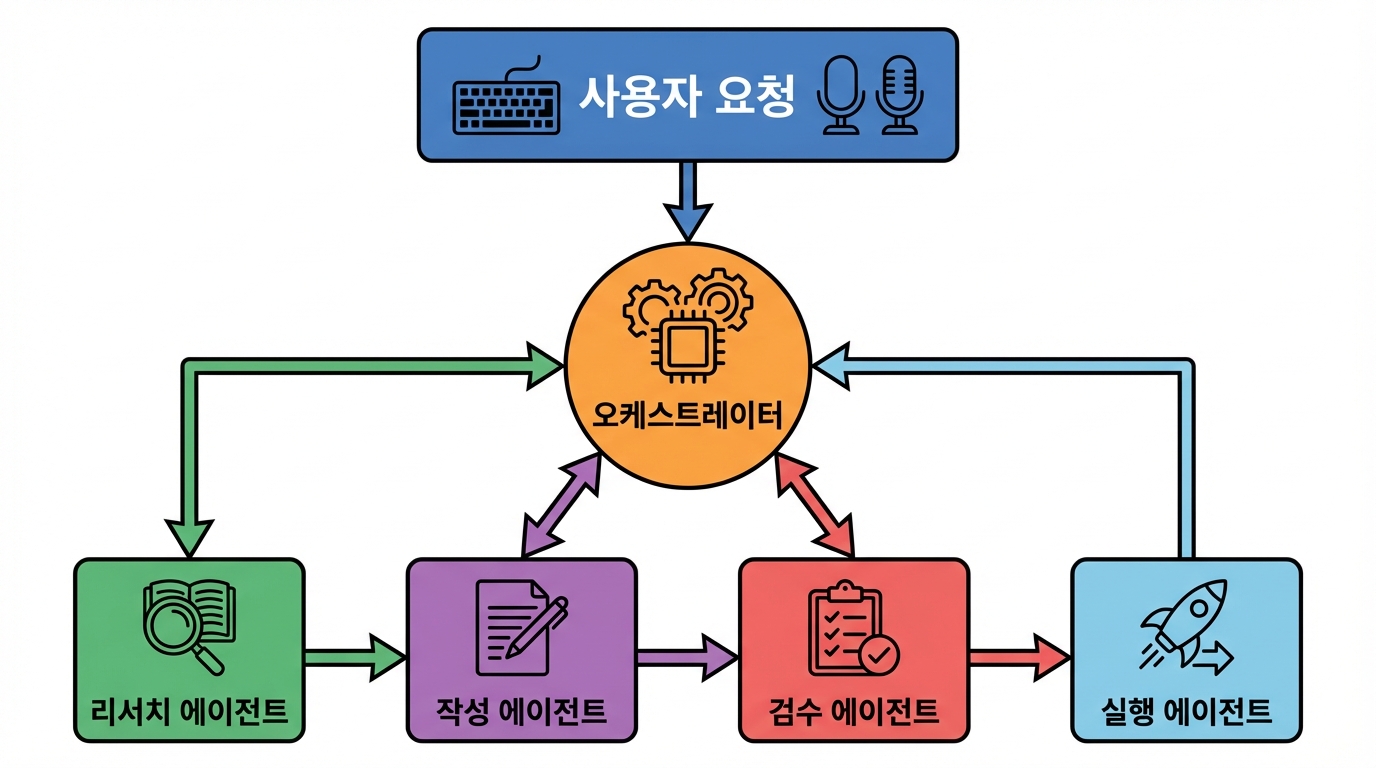
초기에는 중앙 오케스트레이터가 요청을 받아 각 전문 에이전트에게 작업을 배분하는 구조가 가장 다루기 쉽다. 오케스트레이터는 사용자 요청을 해석하고 필요한 하위 작업을 정의한 뒤, 각 에이전트의 결과를 모아 최종 응답을 조립한다. 이 방식은 디버깅과 로깅이 단순해서 실무 도입에 적합하다.
- 입력 수신 에이전트 또는 게이트웨이
- 계획 수립 에이전트
- 실행 에이전트들
- 검증 또는 리뷰 에이전트
- 최종 응답 조립기
데이터 계약을 먼저 정해야 한다
에이전트 사이를 자연어만으로 연결하면 초반엔 편하지만 규모가 커질수록 깨지기 쉽다. 그래서 각 에이전트가 주고받는 결과를 JSON 스키마나 명시적 필드 구조로 제한하는 게 좋다. 예를 들어 task, status, result, confidence, next_action 같은 공통 필드를 미리 정하면 조립 과정이 안정적이다.
에이전트 역할을 어떻게 분리할까
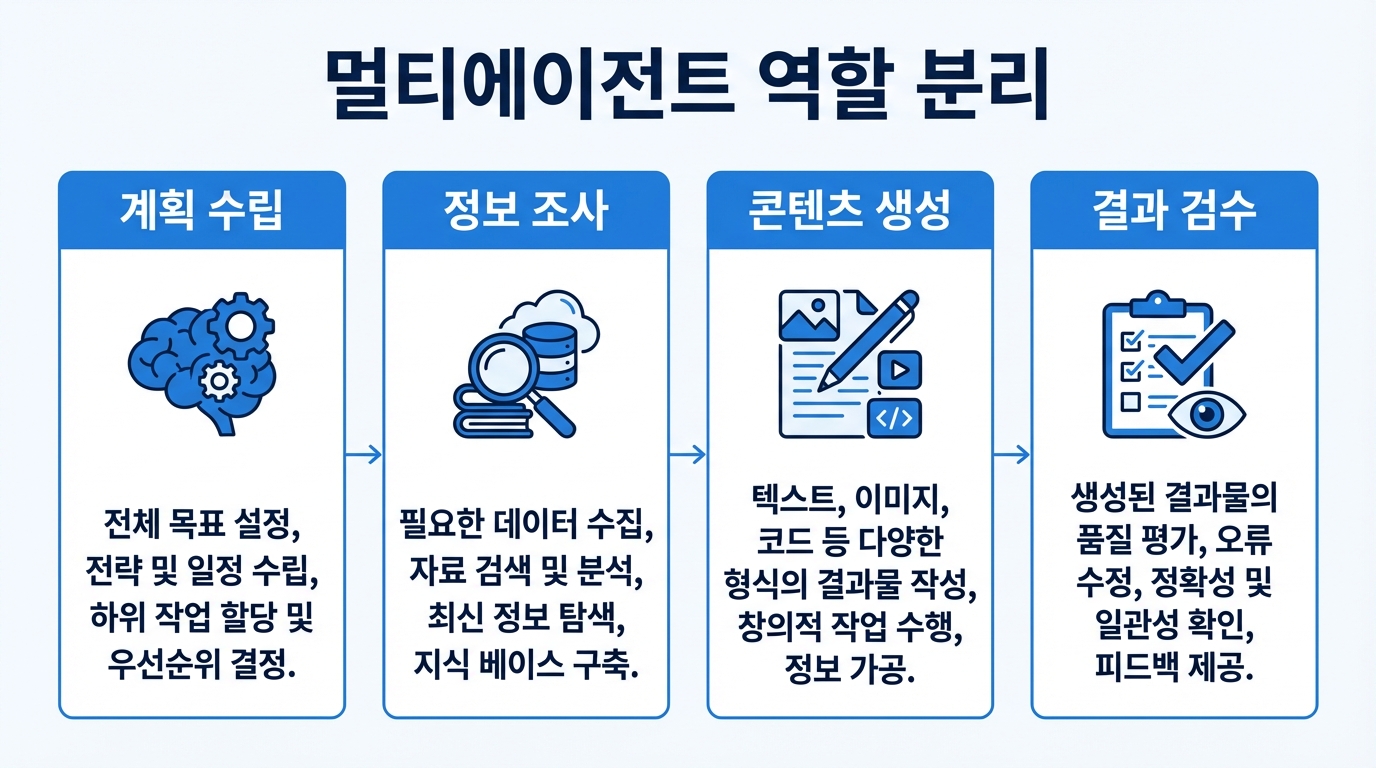
역할 분리는 멀티에이전트 구현하기의 핵심이다. 가장 흔한 실수는 에이전트를 너무 많이 만들거나, 반대로 이름만 다르고 실제 역할은 겹치게 만드는 것이다. 역할 분리의 기준은 기능 이름이 아니라 입력과 출력의 책임이어야 한다.
역할은 능력이 아니라 책임 기준으로 나눈다
예를 들어 “똑똑한 에이전트”, “빠른 에이전트”처럼 추상적으로 나누면 운영이 어려워진다. 대신 “질문 의도 분류”, “관련 문서 검색”, “답변 초안 작성”, “정책 위반 검토”처럼 측정 가능한 책임 단위로 정의해야 한다. 그래야 실패했을 때 어느 단계에서 문제가 났는지 바로 찾을 수 있다.
작게 시작하고 점진적으로 세분화한다
처음부터 10개 에이전트를 만들 필요는 없다. 보통은 3개 정도로 시작하는 게 낫다. 예를 들어 계획 에이전트, 실행 에이전트, 리뷰 에이전트만 있어도 상당히 많은 시나리오를 다룰 수 있다. 이후 병목이 생기는 구간만 별도 에이전트로 분리하면 된다.
- 계획 수립 에이전트: 작업 분해와 우선순위 설정
- 전문 실행 에이전트: 실제 조사, 작성, 호출, 생성 수행
- 검수 에이전트: 오류, 정책, 형식, 품질 점검
오케스트레이션과 상태 관리 핵심
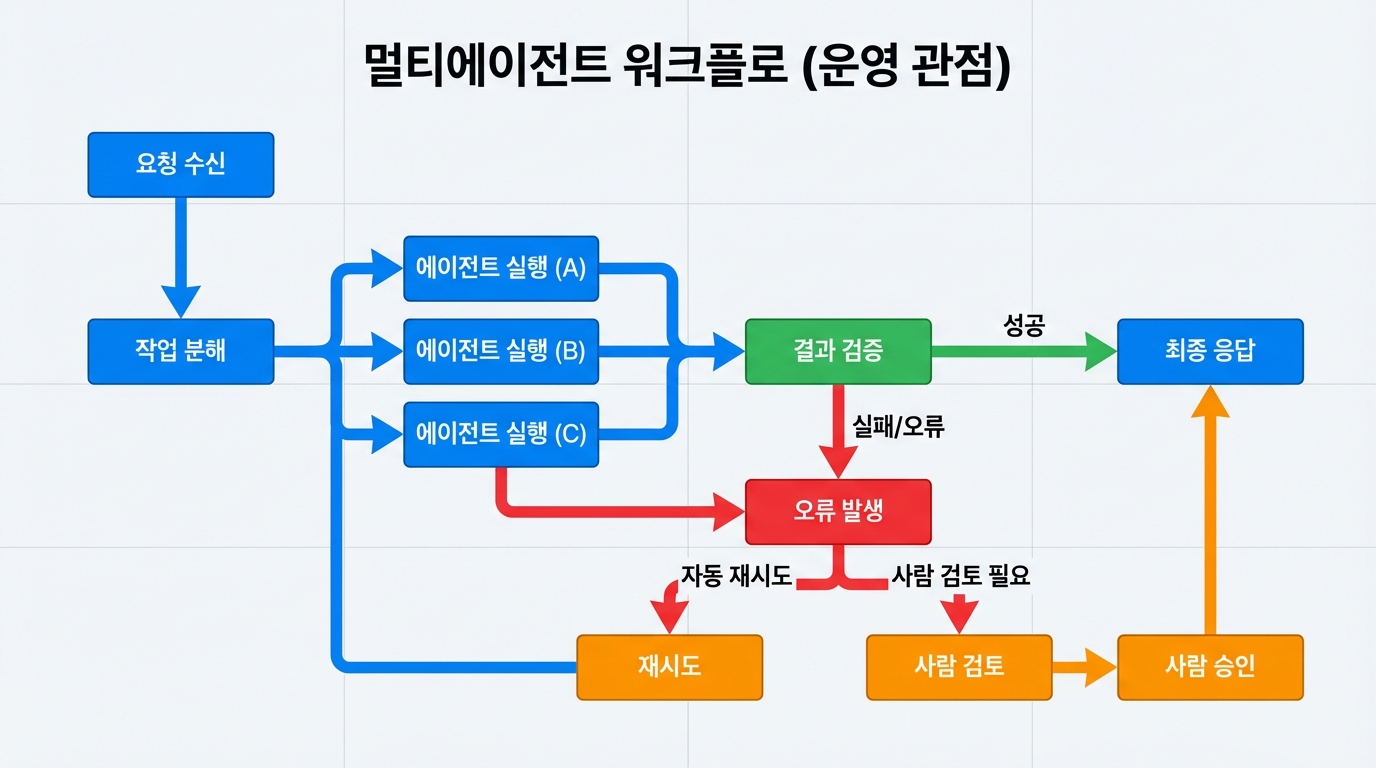
멀티에이전트 구현하기가 실제 서비스에서 어려운 이유는 모델 성능보다 흐름 제어에 있다. 어떤 에이전트를 언제 호출할지, 재시도는 몇 번 할지, 실패하면 사용자에게 어떤 메시지를 보여줄지 같은 운영 규칙이 필요하다. 오케스트레이션 계층이 약하면 에이전트가 아무리 좋아도 전체 시스템은 불안정하다.
상태 저장소를 별도로 두는 편이 안전하다
대화형 시스템이라면 각 단계 결과를 메모리 안에만 두지 말고 외부 저장소에 남겨야 한다. Redis, Postgres, 작업 큐 같은 수단을 활용하면 재시작 이후에도 흐름을 복구할 수 있다. 특히 장기 작업이나 비동기 작업이 섞인 경우 상태 저장이 없으면 장애 대응이 거의 불가능해진다.
재시도와 휴먼 인 더 루프를 함께 설계한다
모든 실패를 자동 재시도로 해결하려고 하면 비용만 늘고 문제는 반복될 수 있다. 따라서 특정 오류는 즉시 재시도, 특정 오류는 다른 에이전트로 우회, 특정 오류는 사람 승인 요청으로 넘기는 기준이 있어야 한다. 이 정책이 있어야 멀티에이전트 시스템이 현실적인 운영 도구가 된다.
- 타임아웃 기준 정의
- 에이전트별 최대 재시도 횟수 설정
- 치명 오류와 경미 오류 구분
- 중간 결과 로그 저장
- 사람 승인 단계 삽입
운영 단계에서 꼭 챙길 체크포인트
개발이 끝났다고 해서 멀티에이전트 구현하기가 끝난 건 아니다. 실제 운영에서는 비용 폭증, 지연 시간 증가, 불필요한 하위 작업 생성, 에이전트 간 충돌 같은 문제가 자주 발생한다. 따라서 관측 가능성, 비용 모니터링, 결과 평가 기준을 초기에 함께 넣는 게 중요하다.
평가 루프를 시스템 안에 넣어야 한다
좋은 멀티에이전트 시스템은 한 번 답하고 끝나지 않는다. 최종 출력이 목표 형식을 만족했는지, 사실 오류가 없는지, 사용자 의도와 맞는지를 자동 점검하는 루프가 필요하다. 간단한 룰 기반 검증과 리뷰 에이전트를 함께 쓰면 품질을 안정적으로 끌어올릴 수 있다.
실무에서는 작은 성공 사례부터 만드는 게 좋다. 예를 들어 “문의 분류 → 문서 검색 → 초안 생성 → 검수”처럼 명확한 4단계 흐름을 먼저 완성하고, 이후 도메인별 전문 에이전트를 추가하는 식이 안정적이다. 너무 큰 그림부터 잡으면 결국 디버깅과 유지보수 비용이 더 커진다.
멀티에이전트 도입 전 점검할 항목
아래 항목을 체크하면 초기 실패 확률을 꽤 줄일 수 있다.
- 문제를 정말 역할 단위로 쪼갤 수 있는가
- 에이전트별 입력과 출력이 명확한가
- 중앙 조정자 또는 메시지 버스 설계가 있는가
- 로그와 상태 저장이 가능한가
- 휴먼 검토 단계가 필요한 작업인가
하네스 엔지니어링에 대해 궁금하면 다음링크를 참조하세요
외부 링크: Google Cloud의 AI 에이전트 설명