
Scrapling은 단순 HTML 파서가 아니라, 적응형 파싱과 스텔스 페칭, Spider 구조를 한 번에 묶은 Python 웹 스크래핑 프레임워크다. 웹사이트 구조가 자주 바뀌거나 안티봇 대응이 필요한 환경에서, 여러 도구를 따로 엮는 대신 하나의 흐름으로 운영하고 싶은 사람에게 특히 눈에 띈다.
요즘 스크래핑 작업은 단순 requests와 BeautifulSoup 조합만으로 끝나지 않는 경우가 많다. 동적 페이지, Cloudflare 같은 방어 장치, 대규모 수집, 세션 유지, 재시도, 프록시 로테이션까지 고려해야 하기 때문이다. Scrapling은 이 복잡한 조합을 줄이면서도, 단일 요청부터 풀 크롤링까지 자연스럽게 확장할 수 있게 설계된 점이 강점이다.
Scrapling이 왜 다시 보이는가
Scrapling이 주목받는 이유는 단순히 기능이 많아서가 아니다. 스크래핑 운영에서 반복적으로 부딪히는 문제를 꽤 현실적으로 묶어냈기 때문이다. 특히 사이트 구조 변경으로 인한 선택자 붕괴, 안티봇 우회, 브라우저 자동화의 무거움, 크롤러 확장 비용 같은 문제를 한 프레임워크 관점에서 풀어낸다.
적응형 파싱이 유지보수 비용을 줄인다
대부분의 스크래퍼는 페이지 구조가 조금만 바뀌어도 CSS 선택자나 XPath가 깨진다. Scrapling은 저장된 요소를 다시 추적하는 적응형 탐색 개념을 제공해, 구조 변경 이후에도 비슷한 요소를 재탐색할 수 있게 한다. 이 차이는 장기 운영에서 꽤 크게 체감된다.
Scrapling은 프로토타입과 운영의 간극을 줄인다
처음에는 한두 페이지를 긁는 용도로 시작했더라도, 나중에는 수집 범위가 커지고 동적 페이지가 섞이기 마련이다. Scrapling은 처음엔 가볍게 시작하고 이후 같은 인터페이스 안에서 확장할 수 있어, 도중에 도구 조합을 갈아엎는 비용을 낮춘다.
Scrapling 핵심 기능 5가지
Scrapling을 소개할 때 꼭 짚어야 할 포인트는 다섯 가지다. 이 다섯 가지를 보면 왜 이 프로젝트가 단순 파서가 아니라 프레임워크로 불리는지 이해가 쉬워진다.
1. 적응형 파싱
Scrapling은 처음 찾은 요소 정보를 저장해두고, 페이지 구조가 달라졌을 때 유사도 기반으로 다시 찾는 adaptive 흐름을 지원한다. 유지보수 인력이 부족한 프로젝트일수록 이 접근의 가치가 크다.
2. 단계별 Fetcher 계층
일반 HTTP 요청용 Fetcher, 브라우저 기반 DynamicFetcher, 안티봇 우회에 초점을 둔 StealthyFetcher가 분리되어 있다. 즉 모든 사이트에 무거운 브라우저를 걸지 않고도 상황에 따라 점진적으로 대응 수위를 올릴 수 있다.

3. Spider 구조
Scrapy 스타일의 Spider API를 제공해 start_urls, async parse, Request/Response 패턴으로 확장할 수 있다. 동시성, 세션 분리, pause/resume, 스트리밍 처리까지 이어지기 때문에 단순 스크립트에서 운영형 크롤러로 넘어가기 좋다.
4. CLI와 MCP 서버
Scrapling은 코드 없이 일부 추출을 해볼 수 있는 CLI를 제공하고, AI 도구와 연결할 수 있는 MCP 서버도 포함한다. 즉 개발자뿐 아니라 AI 에이전트나 자동화 파이프라인과 연결하려는 사용자에게도 진입점이 있다.
5. 빠른 파싱 성능
공개된 벤치마크 기준으로 Scrapling은 lxml 기반 최적화를 통해 BeautifulSoup 계열보다 크게 빠른 수치를 보여준다. 모든 실전 환경이 벤치마크처럼 움직이진 않지만, 적어도 파싱 엔진 성능을 병목으로 두지 않으려는 방향성은 분명하다.
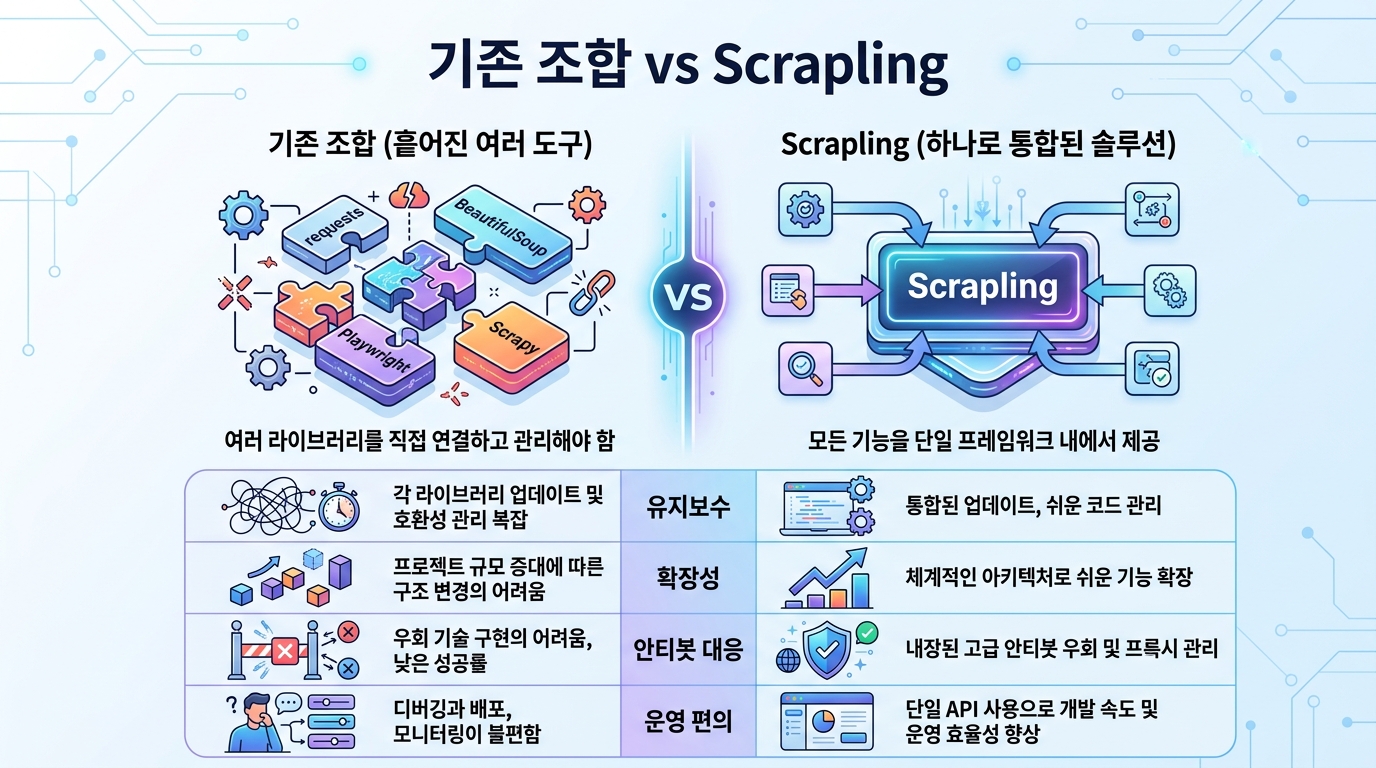
Scrapling이 기존 조합보다 편한 이유
보통 Python 웹 스크래핑은 requests, BeautifulSoup, Playwright, Scrapy, 프록시 회전 로직을 각각 따로 엮는 형태로 커진다. 이 방식은 유연하지만, 프로젝트가 커질수록 유지보수 포인트가 여러 군데로 분산된다는 단점이 있다.
분절된 도구 조합을 한 인터페이스로 묶는다
Scrapling의 가장 실무적인 장점은 도구를 갈아타지 않고 같은 계열 안에서 단계를 올릴 수 있다는 점이다. 단일 요청으로 시작해도, 나중에 세션 관리와 스텔스 페칭, Spider 확장으로 같은 철학 안에서 올라갈 수 있다.
Scrapling은 운영 관점에서 설명하기 쉽다
팀 내에서 스크래핑 스택을 공유할 때도 유리하다. 신규 인력이 들어왔을 때 requests는 여기, 브라우저는 저기, 프록시는 따로, 재시도는 다른 모듈이라는 식으로 설명하는 대신, Scrapling 중심으로 아키텍처를 정리할 수 있기 때문이다.
Scrapling을 어디에 써보면 좋은가
Scrapling은 특히 아래와 같은 상황에서 잘 맞는다.
- 사이트 구조 변경이 잦아 선택자 유지보수가 힘든 경우
- 정적 페이지와 동적 페이지가 섞여 있는 경우
- 처음엔 소규모 수집이지만 나중에 크롤러로 확장할 가능성이 있는 경우
- AI 에이전트와 웹 추출 파이프라인을 붙이려는 경우
- 안티봇 대응과 세션 관리까지 한 도구에서 다루고 싶은 경우
AI 자동화와도 궁합이 있다
MCP 서버를 제공한다는 점은 Scrapling을 단순 개발자용 라이브러리 이상으로 보게 만든다. 필요한 정보만 먼저 구조화해 AI에 넘기면 토큰 낭비를 줄일 수 있어, 에이전트형 자동화 파이프라인에서도 응용 여지가 있다.
Scrapling 도입 전에 체크할 점
물론 Scrapling이 모든 상황의 정답은 아니다. 단순한 정적 페이지 몇 개를 긁는 수준이라면 오히려 requests와 가벼운 파서 조합이 더 빠르게 끝날 수 있다. 또한 강한 스텔스 기능을 사용할수록 대상 사이트 정책과 법적·윤리적 경계도 함께 확인해야 한다.
Scrapling을 강하게 쓸수록 운영 기준도 필요하다
특히 대규모 수집이나 안티봇 우회를 시도할 때는 robots 정책, 요청 빈도, 프록시 정책, 법적 책임 범위를 같이 봐야 한다. 강한 도구일수록 잘 쓰는 기준이 더 중요하다.
도입 판단은 복잡도 기준으로 하는 편이 좋다
현재 작업이 단순 파싱인지, 동적 처리와 우회가 필요한지, 장기 운영인지, 팀 협업이 필요한지에 따라 Scrapling의 가치가 달라진다. 즉 기능이 많다고 무조건 쓰는 것보다, 복잡도가 올라갈수록 선택 가치가 커진다고 보는 편이 정확하다.
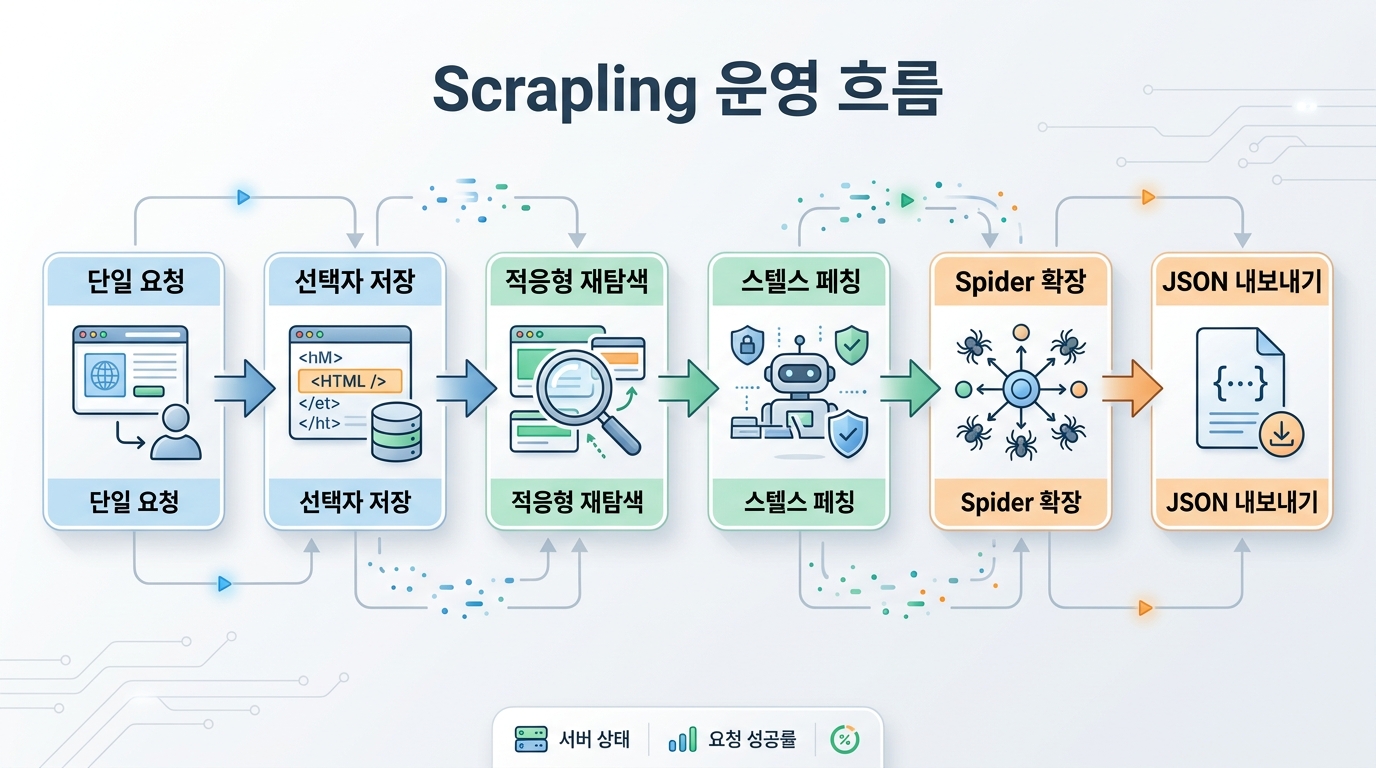
결론: Scrapling은 운영형 스크래핑에 강하다
정리하면 Scrapling은 BeautifulSoup를 대체하는 단순 파서라기보다, 파싱부터 우회, 브라우저 자동화, Spider 크롤링까지 한 흐름으로 묶는 운영형 웹 스크래핑 프레임워크에 가깝다. 특히 적응형 파싱과 단계별 Fetcher 구조, Spider 확장성은 유지보수와 확장성 모두를 신경 써야 하는 프로젝트에서 강점이 분명하다.
Scrapling의 핵심은 기능 수가 아니라, 작은 추출 작업을 나중에 운영형 크롤링으로 키울 때 도구 전환 비용을 줄여준다는 데 있다.
더 실무적인 AI 자동화 글은 이전 워드프레스 AI 인프라 글도 함께 참고할 만하다.
공식 정보는 Scrapling GitHub 저장소와 공식 문서에서 확인할 수 있다.
함께 보면 좋은 의사 운영 사이트
교육, 개원 준비, 홈페이지 제작, 의사 커뮤니티까지 운영에 도움이 되는 사이트를 모았습니다.
-
의사를 위한 통증교육
doctormodu.com → -
의사를 위한 모든 교육
academy.doctormodu.com → -
개원 전 필수패키지
감잡, 통증, 피부, IVNT 모든 족보모음
doctornote.kr → -
의사를 위한 홈페이지 제작
doctorbrand.kr → -
의사들을 위한 소통공간
doctorlounge.kr →